Evaluating LLMs on Structured Classification Tasks
Introduction
Large Language Models have revolutionized classification tasks across industries, from sentiment analysis in customer feedback to document categorization in legal and medical domains. As organizations increasingly deploy LLMs for critical classification workflows—whether it’s triaging support tickets, categorizing user-generated content, or analyzing customer interviews—the stakes for accurate performance have never been higher.
However, evaluating classification quality presents unique challenges: traditional metrics may not capture real-world performance, ground truth labels are often expensive or unavailable, and the nuanced nature of language understanding makes it difficult to assess whether a model truly “gets it right.”
This comprehensive guide explores both established and cutting-edge approaches to LLM classification evaluation, providing practical frameworks for ensuring your models perform reliably in production environments where classification errors can directly impact business outcomes and user experience.
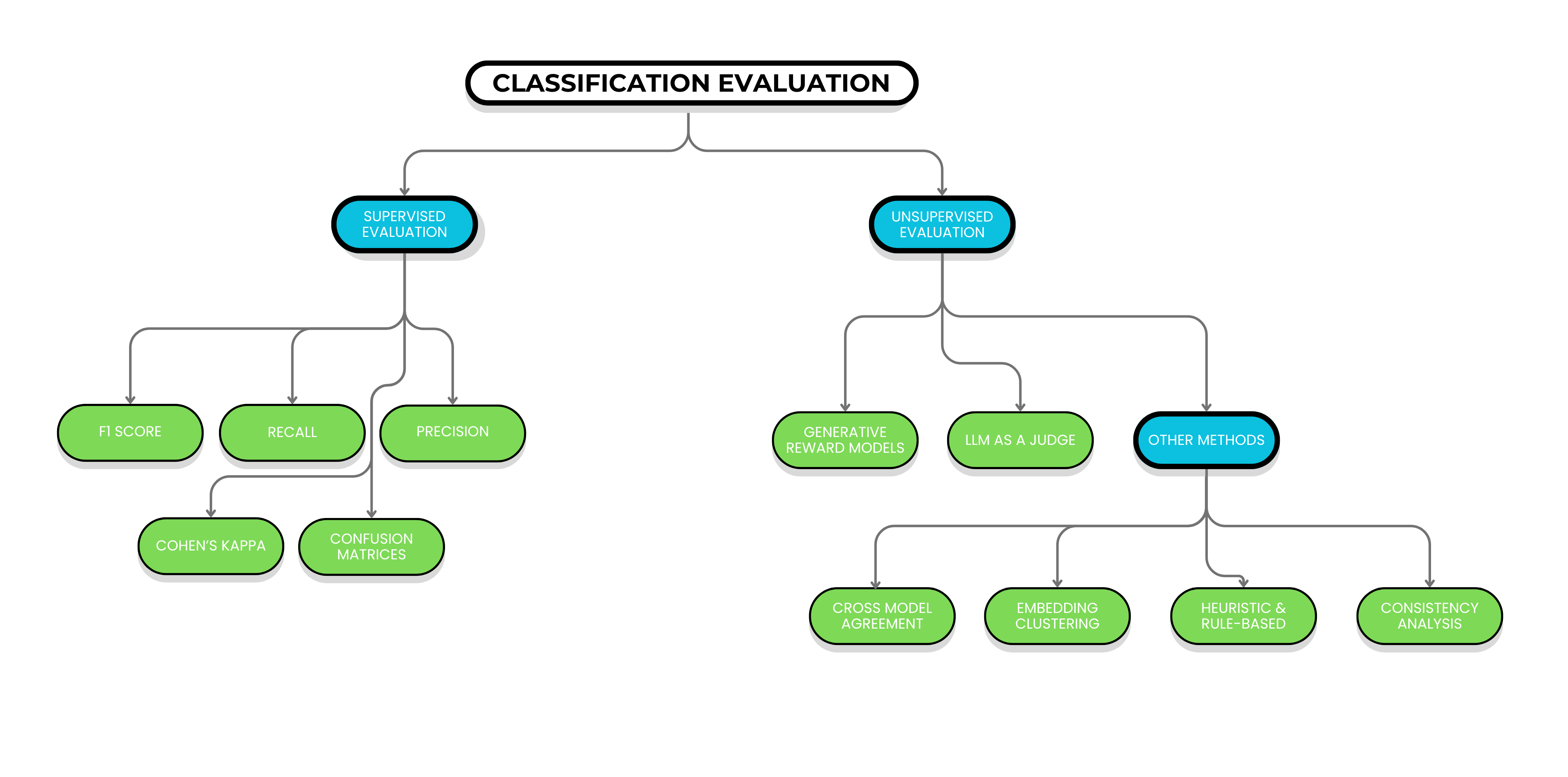
Supervised Evaluation: The Gold Standard
When you have reliable ground truth labels, supervised evaluation remains by far the best approach. Nothing beats actual labeled data for understanding model performance.
Standard metrics for supervised evaluation:
- F1 score, precision, recall for overall performance
- Confusion matrices to identify specific failure modes and category confusions
- Cohen’s kappa for inter-annotator agreement when using human labels
Domain-specific considerations: For customer interviews, track category-specific performance since some labels (like “complaint scenario”) may be more critical than others.
Label-Free Evaluation Approaches
When ground truth labels aren’t available, you have two main options:
- Generative Reward Models (like Composo Align)
- LLM-as-a-Judge
For automated evaluation to work effectively, the evaluator must have some form of leverage over the generator LLM. This leverage can come from:
- More information: Human-provided ground truth or clear specifications not available to the generator
- More compute/time/tokens: Using a more powerful model with extensive reasoning
- Greater focus: Specializing on a single evaluation dimension rather than general generation (in which case there are going to be a large number of competing priorities in system instructions)
- Hindsight: Using outcomes (e.g., from function calls) to retrospectively evaluate decisions
In classification evaluation, the leverage generative reward models & LLM as a judge have, is typically greater focus on specific dimensions & an element of having more information.
Alternatively, you could create synthetic labeled datasets using more powerful LLMs with additional time and reasoning capabilities (if you’re not using a frontier LLM for the classification already).
Generative Reward Models: Easy Label-Free Evaluation
Purpose-built generative reward models like Composo Align represent a rigorous and easy approach to LLM evaluation when labels aren’t available. Key Advantages vs LLM-as-Judge are:
- Performance improvements:
- 89% agreement with expert preferences vs 72% for state of the art LLM-as-a-judge
- 60% reduction in error rate compared to LLM-as-judge approaches
- 100% consistency: Deterministic scoring eliminates run-to-run variation
- Practical benefits:
- Extremely simple implementation: Single-sentence criteria instead of complex prompt engineering
- Quantitative precision: Reliable 0-1 scores for statistical analysis and trend tracking
- Better business correlation: Validated on real-world production datasets rather than academic benchmarks
Let’s walk through implementing Composo for some customer interview transcripts where we are trying to correctly classify and extract customer complaints. Provide Composo with the criterion, the input text & your application’s output, and Composo will return a score & explanation for how well that output meets your criterion.
Let’s use the following criterion:
“Reward responses that correctly identify complaint scenarios when customers express dissatisfaction, report problems, or request resolution of issues”
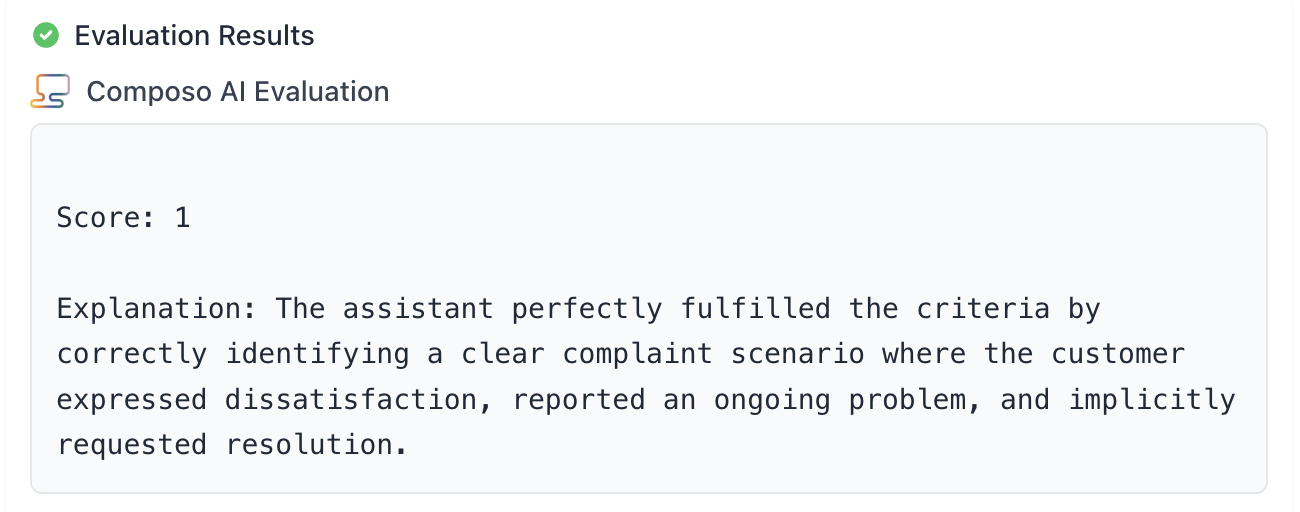
And now for a correct classification example, you can see Composo returns a perfect score.
- Input text: “I’ve been trying to get support for three weeks now, and nobody has responded to my emails. This is really frustrating because I can’t use the product I paid for.”
- Your model prediction: “Complaint scenario”
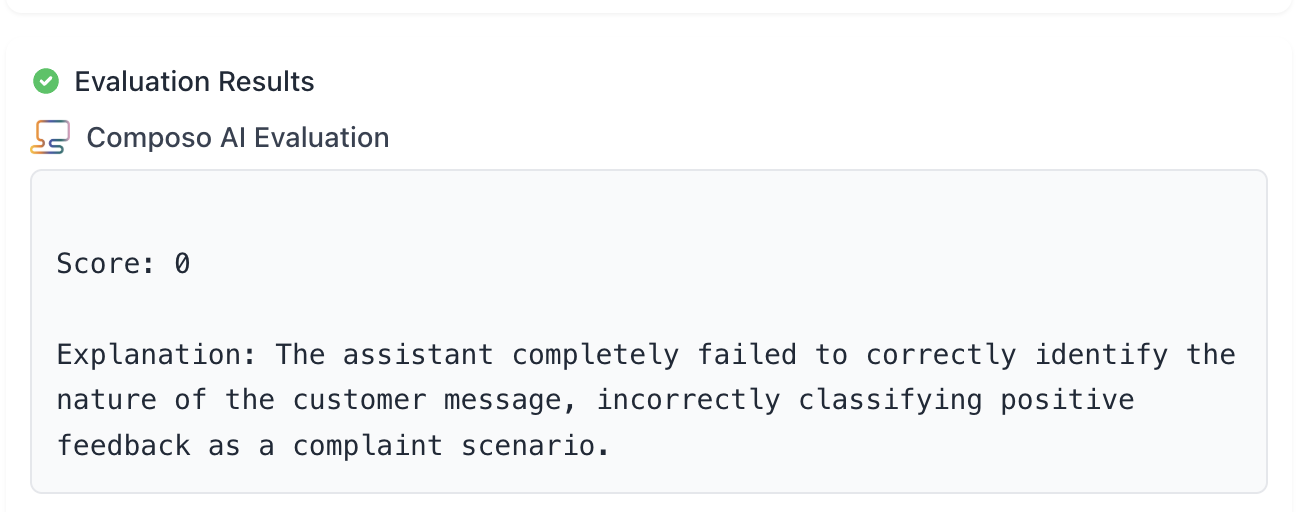
Now an example of an incorrect classification
- Input text: “The team was helpful in explaining the new features during our onboarding call.”
- Your model prediction: “Complaint scenario”
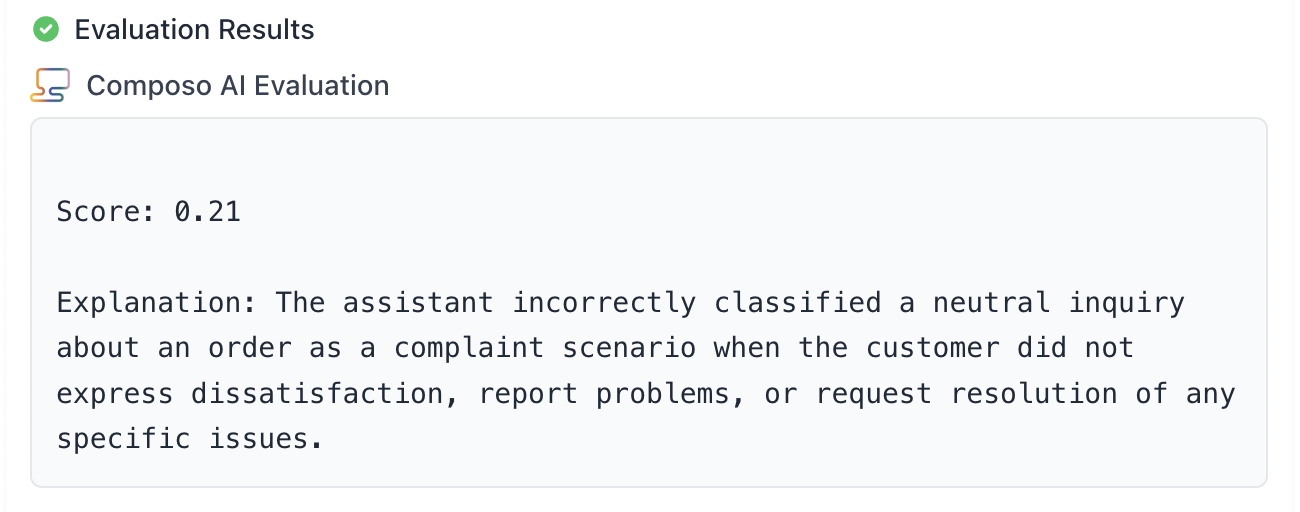
And finally a more nuanced example where it’s unclear whether the classification is correct or not
- Input text: “I’ve been reaching out a few times recently, don’t want to be a bother, but would be great if I could talk about an order please.”
- Your model prediction: “Complaint scenario”
Additional Composo Criteria Examples
Here are a few more example single-sentence criteria you could use with Composo for various classification and evaluation scenarios:
Intent Classification:
- “Reward responses that correctly identify customer intent when they are seeking support, making purchases, or requesting information”
- “Reward responses that accurately distinguish between sales inquiries and technical support requests”
- “Reward responses that properly categorize user queries as account-related, product-related, or billing-related”
Topic Classification:
- “Reward responses that accurately assign documents to their primary subject matter based on content analysis”
- “Reward responses that correctly categorize news articles by topic without being misled by peripheral mentions”
- “Reward responses that properly distinguish between technical documentation, marketing materials, and legal documents”
Relevance Assessment:
- “Reward responses that focus on the main topic discussed rather than tangential mentions”
- “Reward responses that correctly identify the primary concern expressed by the customer”
- “Reward responses that distinguish between central themes and supporting details in documents”
Customer Service:
- “Reward responses that correctly identify when customers are expressing frustration vs. general feedback”
- “Reward responses that accurately detect escalation requests or demands to speak with managers”
- “Reward responses that properly distinguish between feature requests and bug reports”
Document Processing:
- “Reward responses that accurately categorize invoices by vendor type and expense category”
- “Reward responses that properly distinguish between internal memos, external correspondence, and policy documents”
Financial/Legal:
- “Reward responses that accurately identify risk levels in loan applications based on stated criteria”
- “Reward responses that correctly categorize legal documents by practice area and document type”
- “Reward responses that properly assess compliance violations vs. procedural questions”
How to interpret the scores and conduct analysis
Results will be a continuous score from 0.00-1.00
Exact thresholds will depend on use case
- 0.8-1.0: High confidence correct classification
- 0.6-0.8: Likely correct but review borderline cases
- 0.4-0.6: Uncertain, flag for human review
- 0.0-0.4: Likely incorrect classification
For a successful evaluation system:
- Track performance trends over time as you modify prompts
- Compare accuracy across different customer segments
- Identify categories with consistently low scores
- Measure improvement from model upgrades quantitatively
Reasoning analysis
An additional approach to consider if you are outputting any reasoning and analysis with a classification is to structure evaluation criteria that target the reasoning process or additional analysis produced by the LLM classifier. This is not perfect, because one can’t be certain that the analysis or reasoning actually reflect the true process that was used to classify., but it can be a powerful additional approach to consider.
Example criteria:
“Reward responses where the analysis is logical”
“Reward responses where the reasoning has comprehensively considered all options”
“Reward responses where the analysis considers factors in favour and against a classification”
LLM-as-a-Judge: Alternative Label-Free Approach
When specialized evaluation models aren’t available, LLM-as-judge remains a viable option, though with significant limitations requiring careful implementation.
Implementation Best Practices
- Select an appropriate judge model
- Use a different model family from your classifier to avoid narcissistic bias
- Choose the most capable model available (GPT-4, Claude Sonnet, etc.)
- Design effective evaluation prompts
- Clear criteria definition: Explicitly define each category
- Chain-of-thought reasoning: Ask the judge to explain its reasoning
- Binary judgments: Use “correct/incorrect” rather than numeric scores
Critical Limitations
- Inconsistent scoring: Same response might receive different scores on repeat evaluation
- Narcissistic bias: 10-25% favorability toward same-model outputs
- Verbosity bias: Tendency to favor longer, more elaborate responses
- Limited quantitative precision: Difficulty providing reliable numerical scores
Supporting Evaluation Approaches
1. Cross-Model Agreement Analysis
Deploy multiple different model families and measure consensus:
- High agreement: Signals reliable classification
- Disagreement: Flags uncertain cases requiring review
- Implementation: Run same inputs through different models; measure agreement rates
2. Embedding-Clustering Validation
Analyze semantic consistency of classifications:
- Generate embeddings for documents using sentence transformers
- Apply clustering and measure silhouette scores treating predicted labels as cluster assignments
- High silhouette coefficients: Suggest meaningful category separation
3. Heuristic and Rule-Based Validation
Create simple rules for obvious cases:
- Keyword patterns: “complaint”, “dissatisfied” -> negative sentiment
- Phrase indicators: “love this product” -> positive sentiment
- Use case: Quick validation of clear-cut cases
4. Consistency Analysis
Test model stability across variations:
- Multiple runs: Same input with different temperatures
- Prompt variations: Different phrasings of classification instructions
Practical Implementation Framework
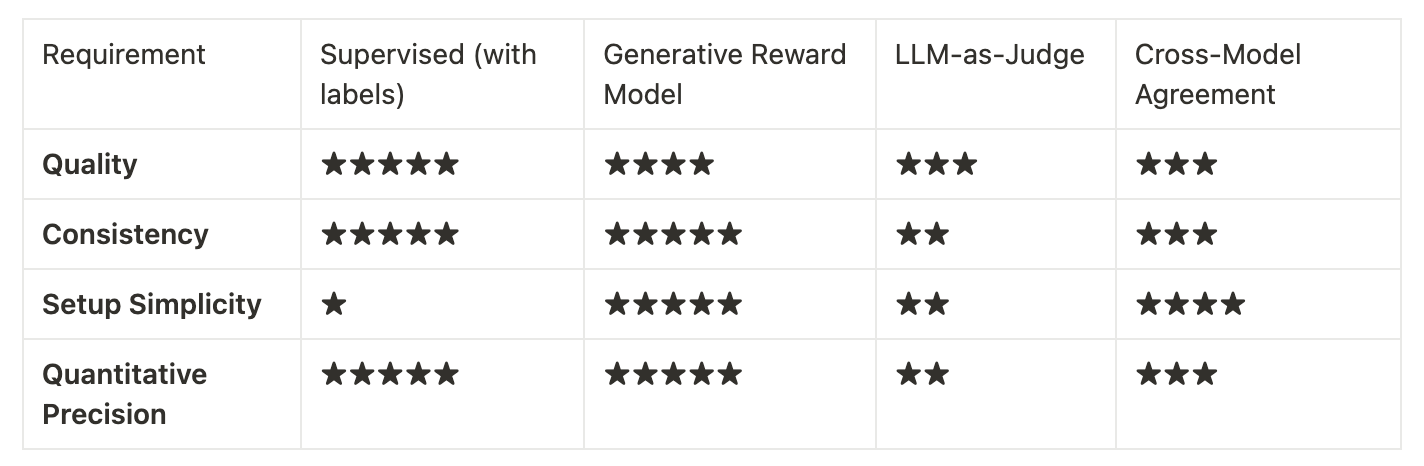
When you have labels: Always use supervised evaluation - it’s the gold standard.
When you need label-free evaluation:
- Primary choice: Generative reward models (Composo) if you want to save time on labeling and setup but can’t sacrifice quality
- Alternative: LLM-as-judge when specialized evaluation models aren’t available
- Supporting: Rule-based validation for obvious cases
In a customer interview use case for example:
-
Implement Composo with focused criteria:
- “Reward responses with accurate sentiment classification based on emotional tone”
- “Reward responses with correct identification of complaint scenarios”
- “Reward responses that offer accurate product category assignment”
-
Set up rule-based validation:
- Negative keywords -> sentiment check
- Problem/issue phrases -> complaint detection
- Product name mentions -> category validation
-
Human validation pipeline:
- Review low-scoring cases
- Monthly audit of random samples
- Track correlation with business metrics
Available Tools and Frameworks
Advanced evaluation:
- Composo Align: Specialized generative reward model with deterministic scoring and simple setup
LLM as a judge approaches:
- OpenAI Evals: LLM-as-judge framework
- DeepEval: LLM-as-judge implementation with chain-of-thought evaluation
Best practices:
- Validate on real-world data: Academic benchmarks don’t translate to business needs
- Focus on business metrics: Ensure evaluation correlates with actual success criteria
- Regular calibration: Validate automated methods against human judgment periodically
Conclusion
- If you have labels, supervised evaluation is unmatched
- For label-free evaluation, generative reward models provide the optimal balance of quality, consistency, and simplicity
- The single-sentence criteria setup dramatically reduces implementation complexity while delivering quantitative precision needed for confident deployment decisions